Extend Your Markdown Workflow With Python
A short tutorial on creating a tag system
Introduction to the problem
As a new employee, I take many notes. I open a new markdown document, name it “2021–09–13” (date of the day), and take notes from meetings, write down questions, todos, and problems.
My notes directory looks like this:
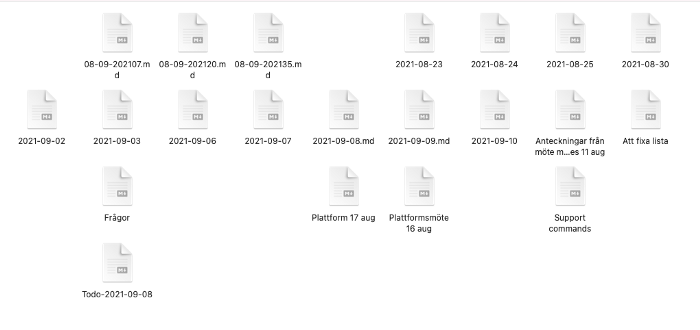
As seen, it’s a mess. The other day I looked for a question I wrote down “a few days ago”. But I just let it slide… I don’t have the time to open 10+ files to look for a little question.
Can’t this be automated somehow?
Yes, yes it can. And it should be.
The solution
Why not extend Markdown with our very own tags?
Let’s have a script look for start and end tags in a specified folder for that specific week, month, day.
The result will look something like this:
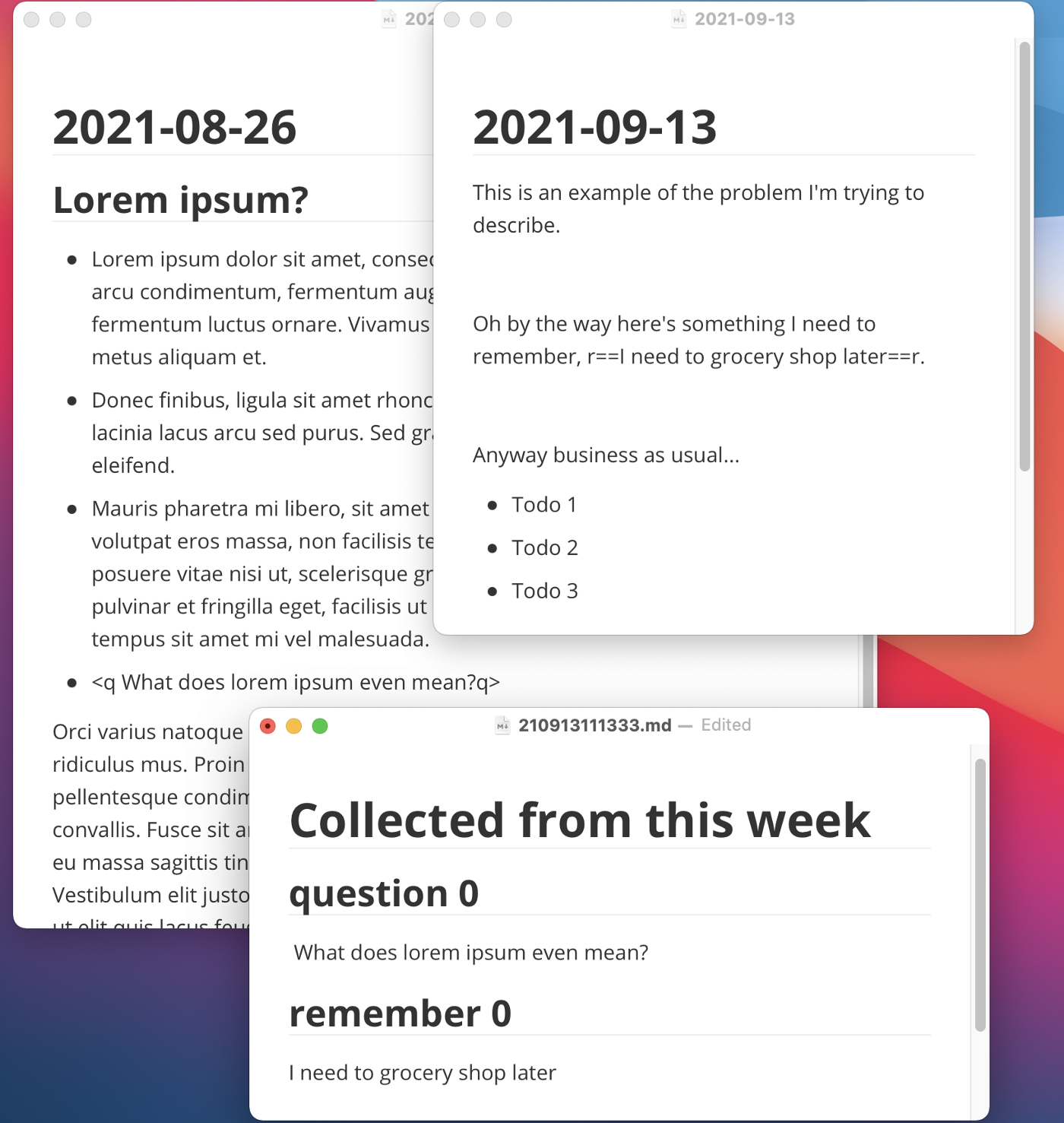
Here I’ve assigned the <q q> tags as questions and the r== ==r as reminders. The Python script generated the file "Collected from this week".
The tutorial
The end product is available here.
Here’s the outline of our script:
- Specify tags we want to look for
- Read files from a specific folder
- Determine if we’re inside or outside a tag
- Gather our result
- Loop through our result and generate a pretty output file
Read a file and detect tags
We want to collect tags where the open tag is <i and close tag is i>, the "i" is for "idea".
Create a markdown file:
echo "# This is the title\n\nHere is a line\n\nMarkdown actually uses two newline characters." > step_1.md
Create a python script in the same directory and write the following:
This is what I got:

It basically reads line by line.
Alright, now we want to filter the lines based on what’s inside of them, update the python script with the following:
Also, update your Markdown file like this:
echo "# This is the title\n\nHere is a line\n\nMarkdown actually uses two newline characters. <i A programming tutorial where you just follow along i>" > step_1.md
I got the following results:
╰─$ python step_1.py
Includes a starting tag: Markdown actually uses two newline characters. <i A programming tutorial where you just follow along i>
Includes an end tag: Markdown actually uses two newline characters. <i A programming tutorial where you just follow along i>
Since the start and end tag is in the same line, it prints the same line.
Extract the tag information
Okay, we can detect tags. It’s a pretty basic job. We now need to extract the actual information.
To extract the information we:
- Find the position of the first tag.
- Extract everything after.
- Stop extracting when we reach the end tag.
Alright, new markdown file. Run this command:
echo "# Extract my information\n\n## Lorem ipsum?\n\n* Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur feugiat arcu condimentum, fermentum augue sit amet, finibus mi. Maecenas fermentum luctus ornare. Vivamus feugiat nibh dui, sollicitudin sagittis metus aliquam et. \n\n* Donec finibus, ligula sit amet rhoncus tempus, augue quam iaculis erat, id lacinia lacus arcu sed purus. Sed gravida consectetur purus imperdiet eleifend. \n\n* <i A programming tutorial where you just follow along i>\n\n<i\n* An idea with multiple\n* Points\n* Could be useful\ni>\n" > step_2.md
For the sake of this tutorial, I’ll define three different states.

Transform the above table into an if-statement:
The pass statement is there temporarily.
State: Start tag
Here we want to:
- Remove everything in the
linevariable until the<itag. - Set the
inside_tagvariable to True.
My output:

With this in mind we get this:
Moving on…
State: End tag
- We need to look for the position of the end tag
- Read until that position
- Put the result into the
idea_list
To look for the position we’ll do the same things as in Start tag,
end_tag_index = line.index("i>")
.
Read until that position:
line = line[:end_tag_index].
Now, a little issue. We don’t know where we want to add the idea in the
idea_list. Index 0, index 5? Who knows.
That’s why we’ll introduce an idea_counter, to keep track of which idea we're at.
Of course, we now need to change the inside_tag variable to False, since we're not inside a tag.
Here is the sum-up of the above:
State: Extract
The extraction part is the easiest. We just read the line, and add it to our current idea.
To see what we got so far, add this to the bottom of your file:
print("Idea_list: ", idea_list)
.
I got the following output:
╰─$ python step_2.py
Idea_list: [' A programming tutorial where you just follow along ', '\n* And idea with multiple\n* Points\n* Could be useful\n']
And that’s pretty much what it should look like!
Creating our output file
We got the list with the ideas. Now we need to display them in markdown.
- Close the previous file pointer:
markdown_fp.close() - Open up a new one:
output_fp = open("output.md", "w") - Write the title:
output_fp.write("# Collection of ideas") - Loop through the ideas and write them as well:
Lastly, close the file pointer: output_fp.close()
My current step_2.py file looks like this:
I created the start_t and end_t variables to make it easier to change tag characters.
This is my output.md file:
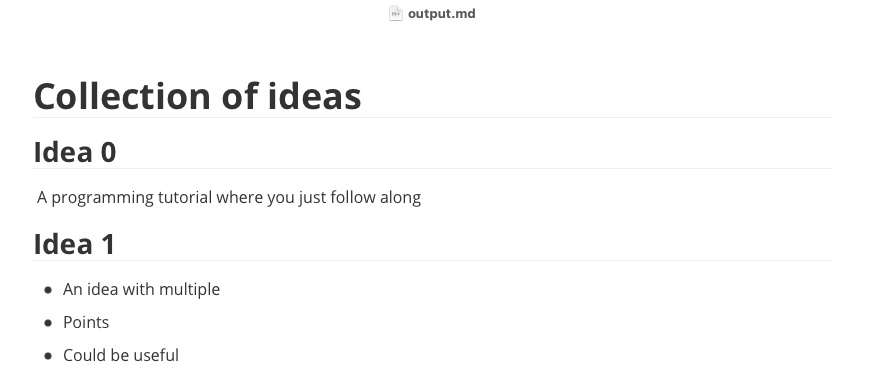
What can we do from here?
Well, the basic idea is pretty much done.
I have created a hulk version of our script which can be seen here:
It’s even shorter than our step_2.py
version. This is because I moved some code to a file called lib.py
, where I also created a class I call tag_checker
. Now I can just add new tags using tags.add_tag("name of tag", "<n", "n>").
Challenge!
Are you new to Python?
Then I challenge YOU to recreate the class called tag_checker . You should do this just from looking at how I use it in the code snippet above.
It’s a challenge that could be considered difficult depending on your knowledge level, however, if you read this far, you’re ready!
Thank you for reading!
This article was my first in a very long time so I appreciate that no one other than you took the time to read it!
If you’re an experienced programmer, maybe you appreciated the idea of automating your markdown workflow, or you might even think the code looked neat?
If you’re a beginner programmer I hope it was helpful (and fun!) to follow this tutorial.
I also welcome you to join me for other tutorials.
Let's have a chat
Did you find anything especially interesting about this post, or do you have feedback to us? We are always open for discussion and eager to hear your thoughts and ideas!
Write us a comment to get in touch 👋🏼